W tym wpisie przedstawię ogólną strukturę i kluczowe elementy zbudowanego przeze mnie prototypu projektu. Wpis jest poglądowym podsumowaniem na co należy zwrócić uwagę przy budowie takiego systemu.
Zbudowany przeze mnie prototyp inteligentnego systenta w formie chatu, pozwala na uzyskiwanie informacji z relacyjnej bazy danych. Użytkownik zadaje pytanie w formie tekstowej, a chat odpowiada opierając się na informacjach uzyskanych z bazy relacyjnej.
Jest to system jednoagentowy oparty o RAG oraz narzędzie function calling modelu językowego.
Pod wskazanym linkiem można zapoznać się ze strukturą bazy udostępnionej przez postgres na licencji otwartej. Baza przedstawia wypożyczalnię płyt dvd: https://neon.com/postgresql/postgresql-getting-started/postgresql-sample-database. To właśnie na tej bazie jest oparty mój prototyp.
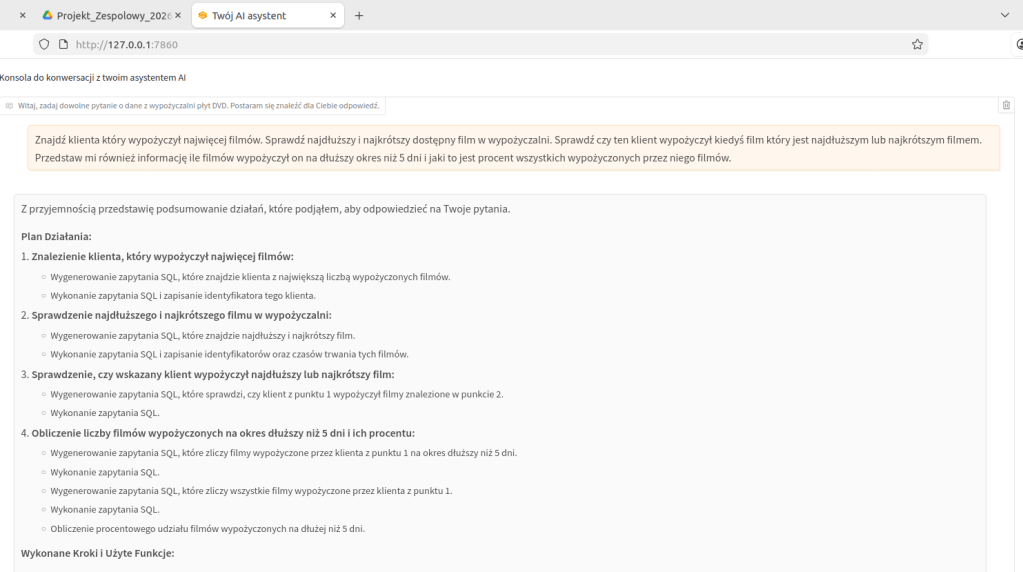
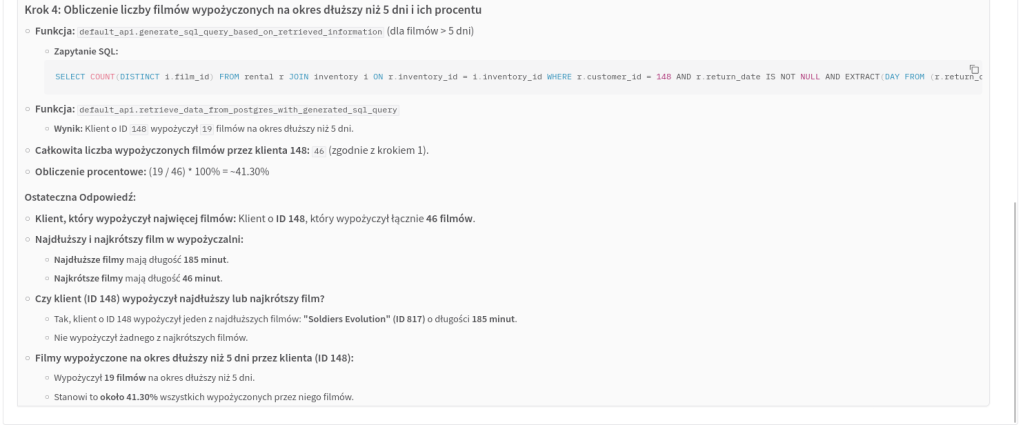
Przykładowe działanie asystenta na bardziej złożonym pytaniu użytkownika:

Aby LLM mógł tworzyć poprawne zapytania SQL, potrzebuje odpowiedniego kontekstu. Dzięki niemu model podczas generowania kodu uwzględni strukturę bazy danych (tabele, kolumny, typy danych oraz informacje biznesowe). Dodatkowo system dostarczy mu przydatne przykłady gotowych zapytań, najlepiej dopasowane do pytania użytkownika.
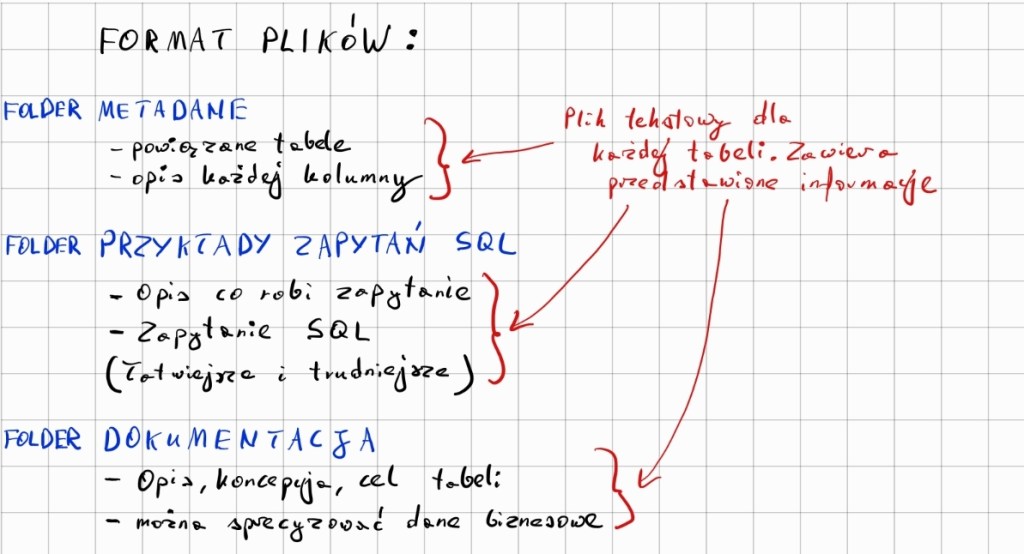
Struktura plików opisujących bazę relacyjną
Metadane: opisują strukturę tabel – ich kolumny, relacje i ograniczenia. Są to kluczowe informacje, dzięki którym LLM może wygenerować poprawne zapytanie SQL, dające się wykonać na bazie i zwracające pożądane dane.
Przykłady zapytań SQL: wskazują modelowi, że powinien stosować konkretny dialekt (np. PostgreSQL, gdyż składnia SQL różni się w zależności od silnika bazy). Gotowe wzorce stanowią dla modelu punkt odniesienia, co znacznie minimalizuje ryzyko błędów – zwłaszcza przy tworzeniu bardziej skomplikowanych zapytań
Opisy biznesowe: choć nie są absolutnie niezbędne, pomagają modelowi zrozumieć nieoczywiste zależności w danych. Dostarczają dodatkowego kontekstu o logice firmy, co bywa kluczowe w specyficznych sytuacjach.
Baza wektorowa – Qdrant
Do przechowywania informacji i późniejszego wyciągania najbardziej skorelowanych fragmentów (chunków), korzystam z bazy wektorowej Qdrant. Poniżej znajduje się przykład fragmentu, który zawiera przykładowe zapytanie SQL. Jest on przechowywany w pojedynczym wektorze.

Podglądając jakie fragmenty tekstów są przechowywane w danych wektorach, mogłem zaznaczyć przybliżone grupy kontekstów których dotyczyły. Widzimy że są to pewne grupy punktów. Te blisko siebie dotyczą mniej więcej tego samego tematu.
RAG – Retrieval Augmented Generation
Jest to podejście polegające na wyszukiwaniu dokumentów najlepiej dopasowanych do zadanego pytania. Znalezione fragmenty służą jako kontekst dla modelu LLM, który na ich podstawie generuje ostateczną odpowiedź w formie tekstowej. Poniżej zamieszczam grafikę wizualizującą ten proces – mam nadzieję, że jest wystarczająco czytelna.
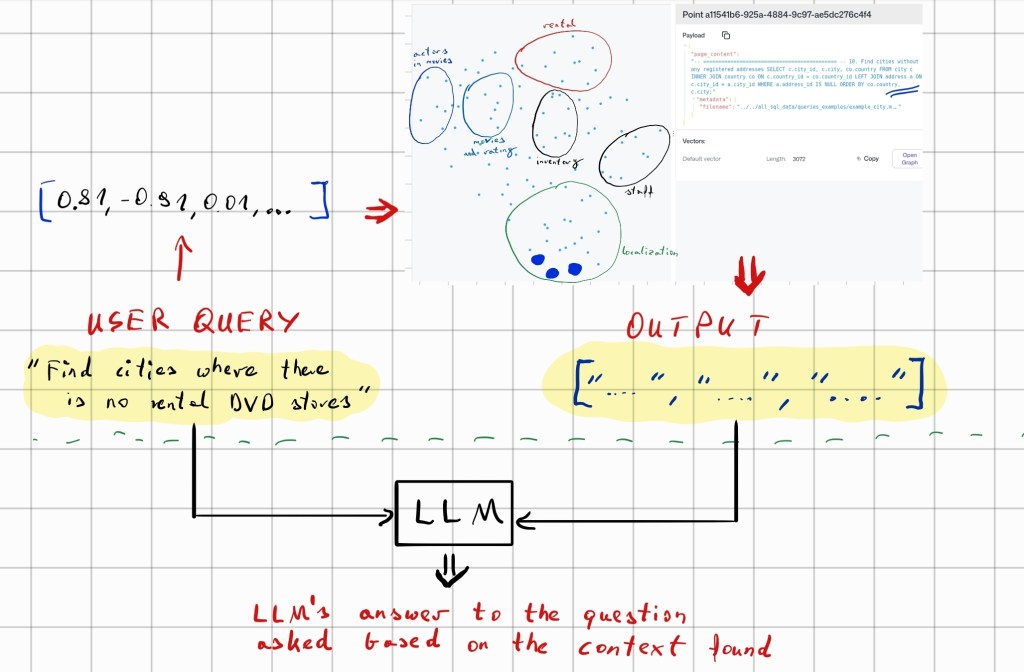
Taki właśnie RAG użyłem w prototypie aplikacji. Model LLM przed wygenerowaniem zapytania SQL, potrzebuje wiedzieć jaka jest struktura bazy relacyjnej. Inaczej nie będzie wiedział jakie są nazwy tabel i co one przechowują.
Przybliżony schemat projektu
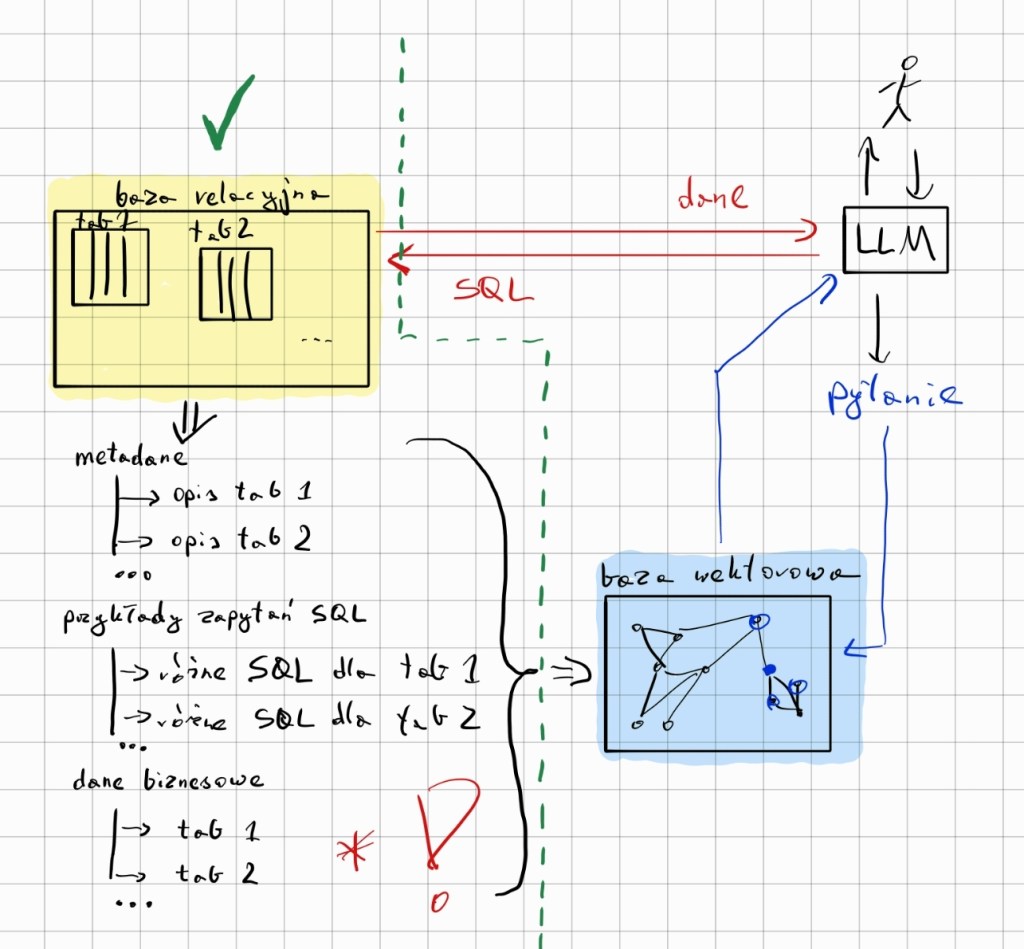
Przepływ danych systemu
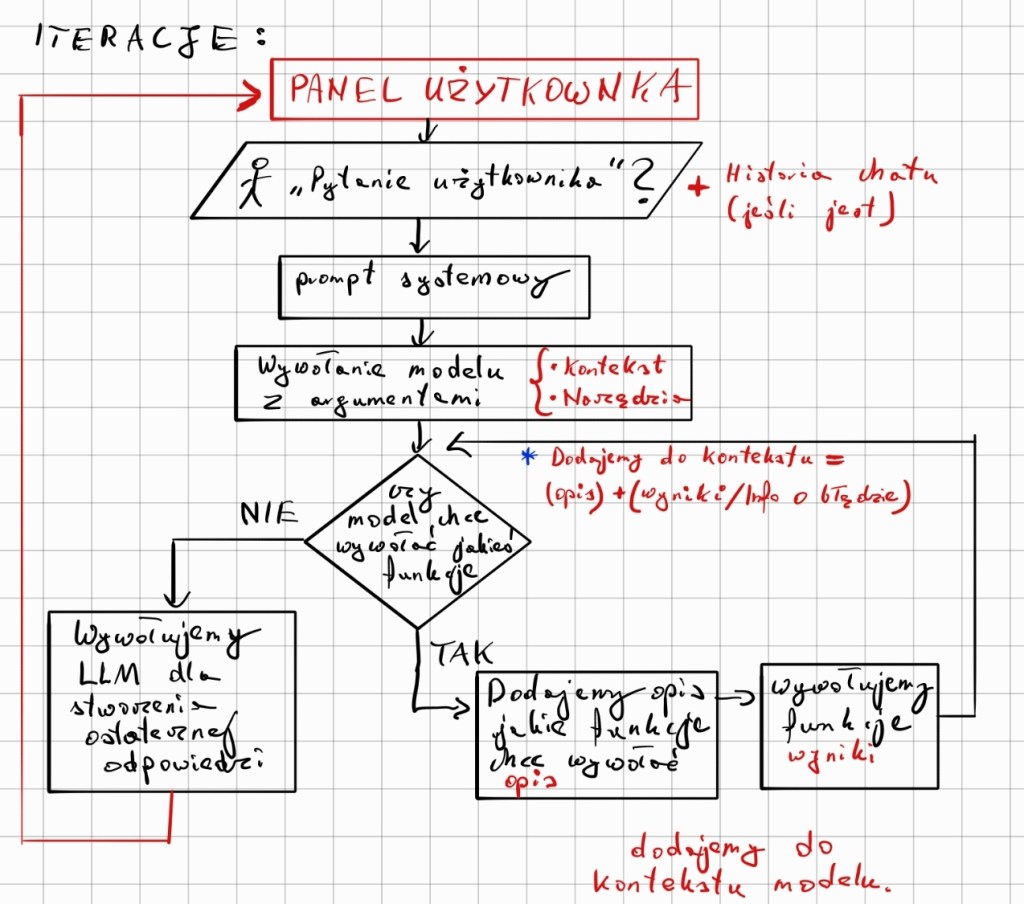
Function calling
Jeśli LLM uzna, że do odpowiedzi na pytanie użytkownika brakuje mu kontekstu, wskazuje w swojej odpowiedzi funkcje, które należy wykonać.

Aby LLM wiedział jaką funkcję wybrać, każda z nich jest odpowiednio opisana w pliku .json. Poniżej przedstawiam fragment tego pliku opisujący funkcję, która wyciąga informacje z bazy wektorowej i generuje pytanie SQL:
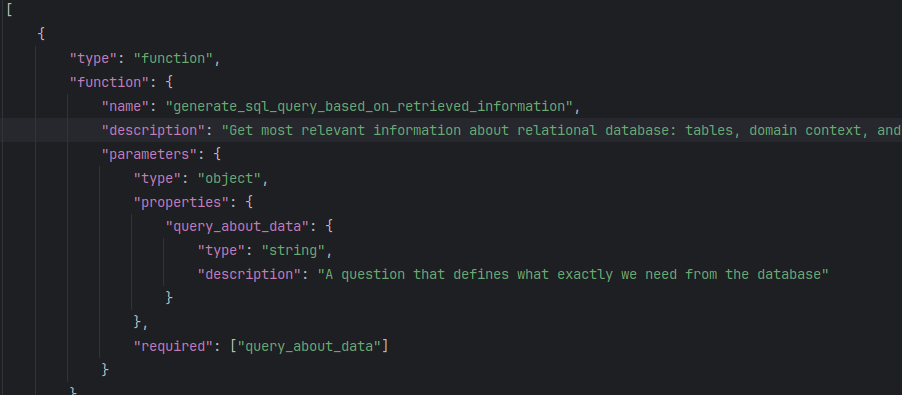
Mam nadzieję że wpis był ciekawy i obrazowy.
Dziękuję za uwagę 🙂

Dodaj komentarz