The unsupervised learning searching for patterns and characteristics of data that we want to analyze. These Data are no labeled, so we can’t use methods from supervised learning.
Clustering is the basic algorithm of unsupervised learning. Clustering – groups the points of the similar features. So for example we have the diameter and color of the measured molecules. When we put this 2 features into the scatter plot it can show for example the three areas where the data appears.
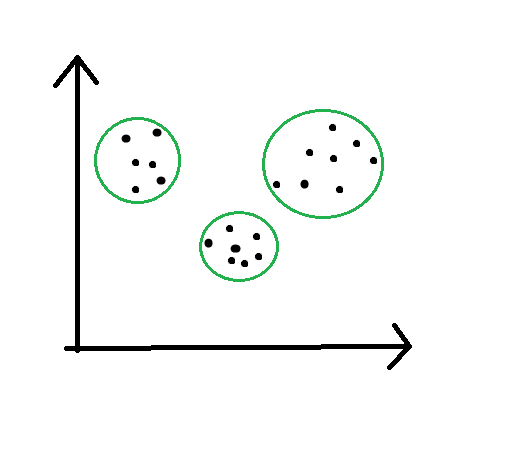
So, as we see here are three clasters (areas, groups) – so the three data behaviour. The stupidest reason I’ve come up with might be: some molecules could be happy, others could be sad and others could be undecided. We just want to find the patterns and use them to next unseen data).
Next example: we have the 10 articles about some topics. We find the words that occur there. And based on this information we split the articles to familiar topics. So some of words in American Fotball article are familiar to Basketball article but wont fit with James Bond article. The patterns here can be: a lot of worlds „ball” appears in two articles, so this articles are familiar. Next pattern: the most common word in 2 articles is „invincible” and it appears 3 times, so the articles about American Fotball and James Bond are very different.
More, soon…

Dodaj komentarz